Discover the Power to Predict the Future
Start planning your next construction project with the data of tomorrow.

Find accurate construction costs for unit line items, assemblies and square foot models to create reliable budget estimates up to 3 years in the future.
Data You Can Trust
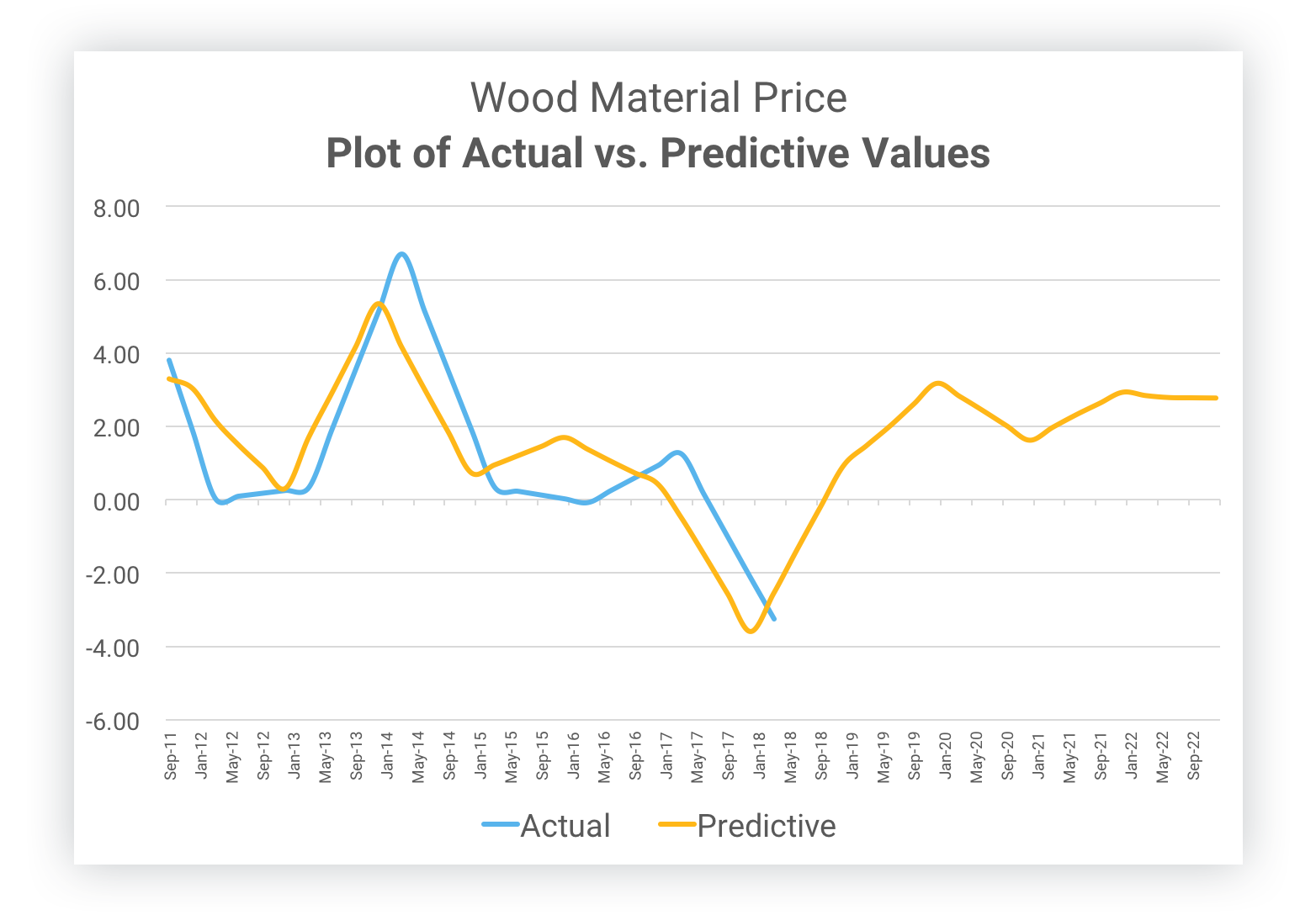
Gordian has collected more than 10 billion data points across 15 years of historical RSMeans data, public government indexes and Moody's private indexes. Data Scientists have applied rigorous statistical data analysis and developed an algorithm to predict material and labor costs. Thorough back-testing found that our predictions were accurate to a maximum error rate of less than three percent.
Costs You Can Control
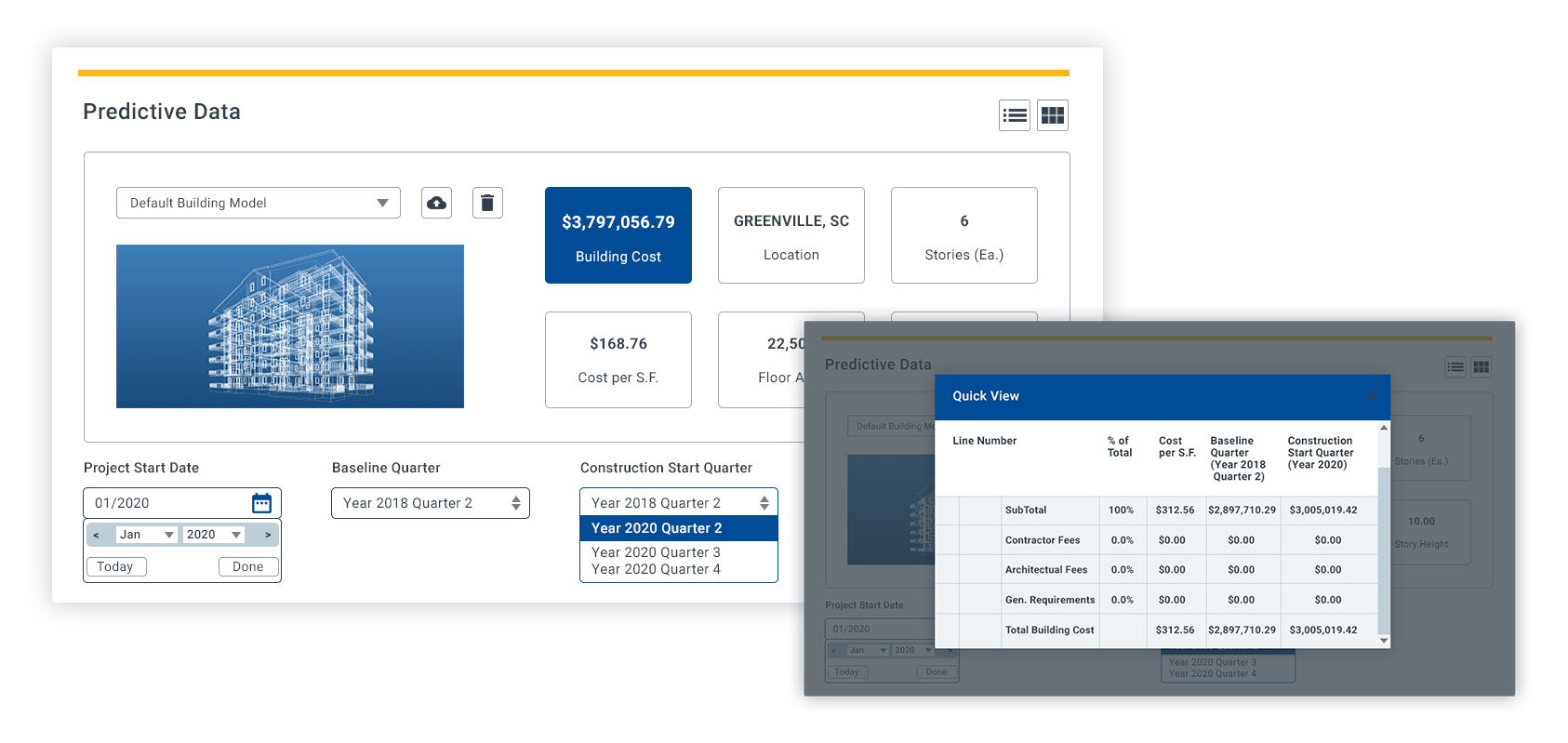
- Analyze building model costs at the square foot or component level.
- Select the optimal time to build by honing in on the quarter you plan to break ground and tracking changes over a three year period.
- Determine the best location to build by comparing cost variances amongst more than 970 cities across North America.
Predict future construction costs within 3% degree of accuracy.
An Industry Game-Changer
Why is predictive technology important?
For decades, people have been building tomorrow's projects with yesterday's data. To keep pace with modern times, the demand for accurate and agile construction costs is a necessity, not an option.
What is predictive data?
Our Data Scientists rigorously analyzed thousands of indexes to develop an algorithm smart enough to account for market fluctuations up to three years into the future.
Who benefits from predictive cost data?
All professionals involved in estimating will find value in more accurate future costs. Owners or builders will benefit from the ability to account for delayed project starts or a large scale, long term period of construction.
How do you know the data is accurate?
Through a process referred to as back-testing, the data predicted by the algorithm is compared to actual historical data indexes. The result showed a deviation of less than three percent on average.
Explore the Value of Predictive Cost Data
Start Using Predictive Cost Data Today
Quickly Access Building Models
Ready to learn more about creating conceptual estimates with predictive cost data? Start with our library of more than 100 commercial construction building models.
Layer in Your Own Data
Interested in applying predictive cost data to your own building standards and specifications?